Python in Excel 中的公开预览:将 Python 和 Excel 分析有机结合
Python 是当今最受欢迎的编程语言之一,深受企业和学生的喜爱,而 Excel 是一种必不可少的工具,用于组织、操作和分析各种数据。然而,直到现在,还没有一种简单的方法可以让这两个世界共同运作。
今天,我们非常高兴地介绍Python in Excel 中的公开预览——在同一 Excel 网格中实现 Python 和 Excel 分析的集成,以实现连续的工作流程。
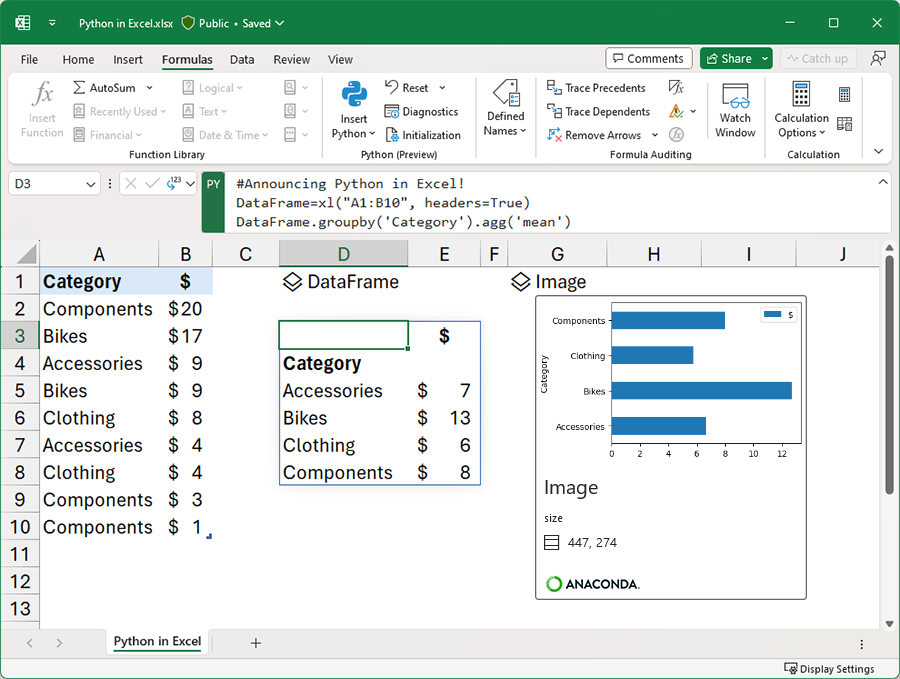
Python in Excel 中将 Python 强大的数据分析和可视化库与您熟悉和喜爱的 Excel 功能相结合。您可以使用 Python 绘图和库在 Excel 中操作和探索数据,然后使用 Excel 的公式、图表和数据透视表进一步优化您的洞察力。
无缝工作
现在,您可以通过直接从 Excel 功能区访问 Python 在熟悉的 Excel 环境中进行高级数据分析。无需设置或安装。使用 Excel 内置的连接器和 Power Query,您可以轻松将外部数据带入 Python in Excel 工作流程中。
我们与 Anaconda 合作,Anaconda 是一家领先的企业级 Python 软件包库,全球数千万数据从业者在使用。Python in Excel 利用在 Azure 中运行的 Anaconda 发行版进行 Python 运行,其中包括最流行的 Python 库,如用于数据操作的 pandas,用于高级统计建模的 statsmodels,以及用于数据可视化的 Matplotlib 和 seaborn。
要查看机器学习和可视化示例,并了解更新,请访问 Excel 官方博客…。
轻松协作
在您喜爱的工具(如 Microsoft Teams 和 Microsoft Outlook)中共享工作簿和 Python 分析。通过评论和@提及无缝协作,与同事一起进行协同编辑,就像在 Excel 中一样。即使没有激活 Python in Excel,团队成员也可以刷新 Python in Excel 中的分析以获取最新信息。

自动获得企业级安全性
保护您的数据是我们的首要任务,因此我们在 Python in Excel 的设计核心注入了安全性和隐私性。Python in Excel 在 Microsoft Cloud 上运行,作为 M365 连接体验,拥有企业级安全性。
查看客户和合作伙伴对 Python in Excel 的评价

麦金尼 – “在 Excel 中运行 Python 简化了麦金尼的报告工作流程。我们过去需要在 Jupyter Notebook 中操作数据结构、筛选和汇总数据,然后在 Excel 中创建可视化效果。现在我们可以在 Excel 中管理整个工作流程。这将使 Excel 变得更加强大,并使 Python 在整个组织中更加易于使用。作为我职业生涯中最令人兴奋的更新,Python 支持是 Excel 的最大亮点!” – Greg Barnes,数据和分析执行总监

麦格劳·希尔 – “麦格劳·希尔的理念是为所有人提供教育,我们与微软的合作有助于改善学生访问 Excel 工具,提高职业就业能力。Python 是大学和学院最需求的技能之一,我们对 Excel + Python 的组合感到非常激动,它将为教育工作者和学生提供一个强大的新途径,以更快地进行分析,实现更大的协作和学习,最终将学生引向更加光明的未来。” – Rebecca Olson,高级投资组合总监

毕马威 – “毕马威和微软正在大力投资于提供先进的基于云的税务技术。在毕马威,我们对 Python in Excel 中的影响感到兴奋,这对我们的税务客户来说意义重大。在 Microsoft 云提供的数据和安全性承诺的支持下,Python 有可能增强高级分析的 Excel 体验,同时为公司提供透明度、简易性和对财务状况更深入的洞察力。” – Tejas Varia,税务数据与分析主管
而我们的工作才刚刚开始。敬请期待更多令人激动的消息!
通过 Python in Excel 使您的数据分析更加强大,讲述更好的故事。
开始使用 Python in Excel
对于在 Microsoft 365 Insiders 计划 Beta 频道中的人们,Python in Excel 正在进行公开预览。此功能将首先在 Windows 版的 Excel 中推出,从构建 16818 开始,然后在以后的日期推出到其他平台。
要使用 Python in Excel,加入Microsoft 365 Insiders 计划。选择 Beta 频道 Insider 级别,以获取 Excel 应用程序的最新版本。
安装最新的 Excel Insider 构建后,打开一个空白工作簿,然后执行以下步骤。
- 在功能区中选择“公式”。
- 选择“插入 Python”。
- 在弹出的对话框中选择“尝试预览”按钮。
还没有收到吗?这可能是我们的问题,而不是您的问题。功能会随着时间的推移发布,以确保一切正常运行。我们会突出显示您可能尚未拥有的功能,因为它们会逐渐发布给更多的内测人员。有时根据您的反馈,我们也会移除某些元素以进行进一步的改进。尽管这很少见,但我们还保留了在产品中完全取消某个功能的选择权,即使作为内测人员,您也有机会尝试它。
在预览版中,Python in Excel 将包括在您的 Microsoft 365 订阅中。在预览版之后,某些功能将在没有付费许可证的情况下受到限制。有关在正式发布之前将提供更多详细信息。
加入 Microsoft 365 Insiders 计划。成为第一个了解 Microsoft 365 应用程序和服务中的下一步内容的人,分享您的反馈,并加入我们的内测社区!
注册以获取有关 Python in Excel 未来可用性的通知
下一步的期望
如上所述,我们正在向 Insiders Beta 频道公开预览 Python in Excel,因此您应该期望很快会有新的功能。请关注以下领域的更新:改进的编辑体验(例如自动完成和语法突出显示)、默认修复、增强的错误行为、帮助和文档等。此外,为了防止滥用,系统目前具有一些数据大小和计算限制,我们将密切监控并进行调整。
我们需要您的反馈!Excel 和 Python 用户可以在应用程序内直接提供反馈(转到“帮助”>“反馈”),在我们的反馈门户上提出改进建议,或在GitHub上与我们的团队互动。
其他资源